Google has announced Gemma 3n, the next generation of its open AI models, and it is a significant step up from what we saw before. After a preview last month at Google I/O, the full version is now here and ready to run directly on your hardware.
For those of you who are not aware, Gemma is a family of open AI models. It is different from Gemini in that it is designed for developers to download and modify, whereas Gemini is Google"s closed, proprietary powerhouse.
The model can now natively process inputs like images, audio, and video to generate text, a leap from just being a text-based model. It can also run on hardware with as little as 2GB of memory, and is supposedly better at tasks like coding and reasoning. Here"s the full list of improvements as outlined by Google:
-
Multimodal by design: Gemma 3n natively supports image, audio, video, and text inputs and text outputs.
-
Optimized for on-device: Engineered with a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory.
-
Groundbreaking architecture: At its core, Gemma 3n features novel components like the MatFormer architecture for compute flexibility, Per Layer Embeddings (PLE) for memory efficiency, and new audio and MobileNet-v5 based vision encoders optimized for on-device use cases.
-
Enhanced quality: Gemma 3n delivers quality improvements across multilinguality (supporting 140 languages for text and multimodal understanding of 35 languages), math, coding, and reasoning.
The core of its efficiency is a new architecture Google calls MatFormer. Google uses the analogy of a Russian Matryoshka doll to describe it: a larger model contains a smaller, fully functional version inside.
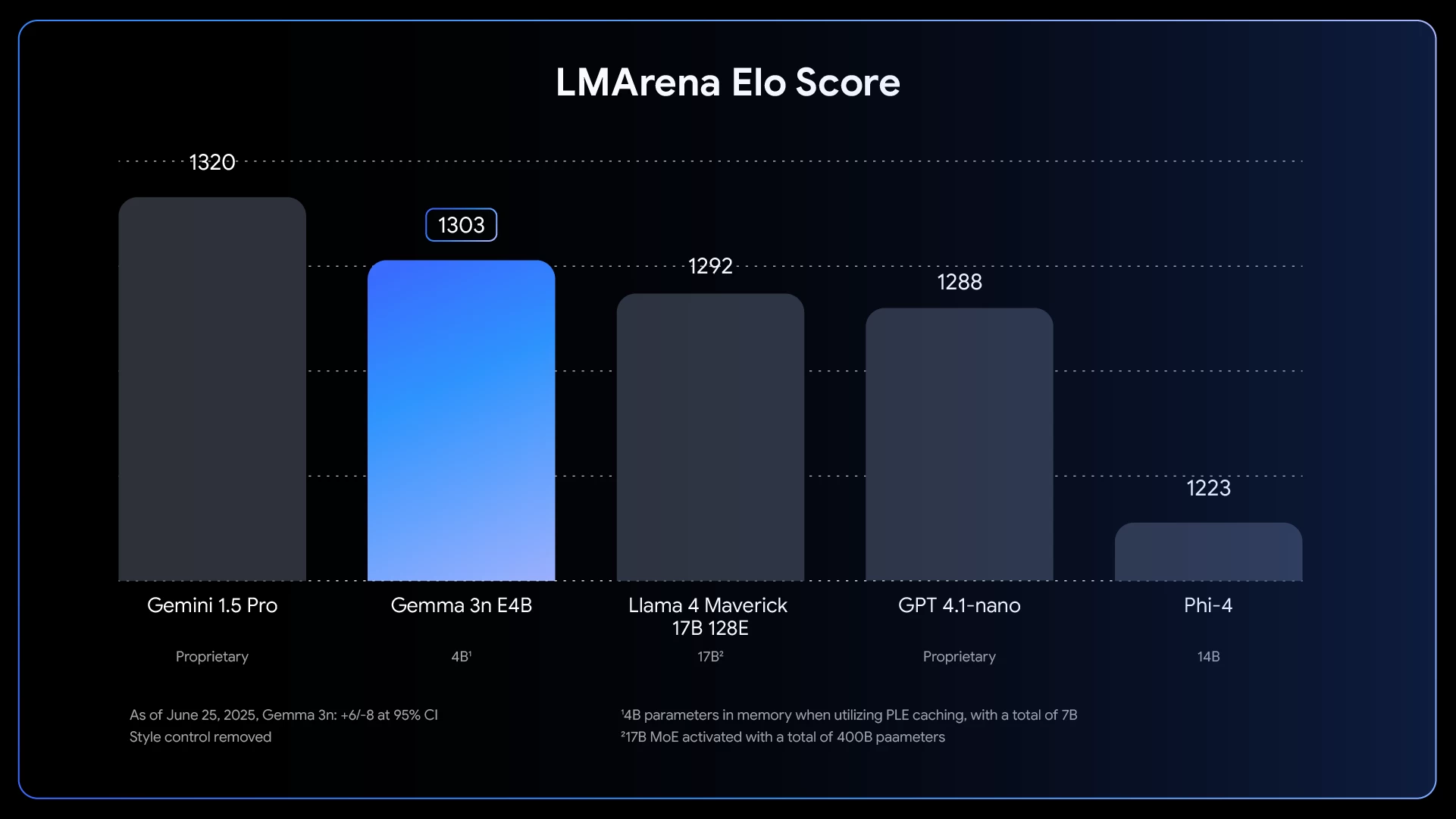
This allows a single model to run at different sizes for different tasks. And as for benchmarks, the larger E4B model is the first model under 10B parameters to break a LMArena score of 1300.
{kind=link}
The model"s audio capabilities now support on-device speech-to-text and translation, using an encoder that can process speech in fine detail. The vision side of things is powered by a new encoder called MobileNet-V5, which is much faster and more efficient than its predecessor. It can process video at up to 60FPS on a Google Pixel device.
If you"re interested, you can start playing with it immediately as the models are available through familiar platforms like Hugging Face and Kaggle, and you can even experiment with them directly in Google AI Studio.
More details can be found in the official announcement post.