{kind=link}
Reddit has filed a lawsuit against Perplexity, as well as three data scraping firms, namely Oxylabs UAB, AWMProxy, and SerpApi, for what the company calls an "industrial-scale" scheme to illegally scrape its platform"s content. The social media giant alleges these companies worked together to bypass its data protections, stealing copyrighted user conversations to train and fuel AI products.
In its complaint filed in the Southern District of New York, Reddit claims that the three scraping companies evade Reddit"s own anti-scraping measures by going through the back door, and in some cases, they scrape Reddit content directly from Google search results pages.
Reddit likened Perplexity to a "North Korean hacker" that will do anything to get the data its "answer engine" desperately needs, instead of entering into an agreement with the platform as companies like OpenAI and Google have done.
The lawsuit tore into Perplexity"s core technology, saying that its technology is "nothing groundbreaking" and that this answer engine is built on "retrieval-augmented generation" ("RAG") where scraped data is processed by another company"s LLM.
In other words, Perplexity’s business model is effectively to take Reddit’s content from Google search results, feed them into a third party’s LLM, and call it a new product. While that business model has somehow translated into a $20 billion valuation, it has not resulted in a willingness to pay for what others (including Google) have."
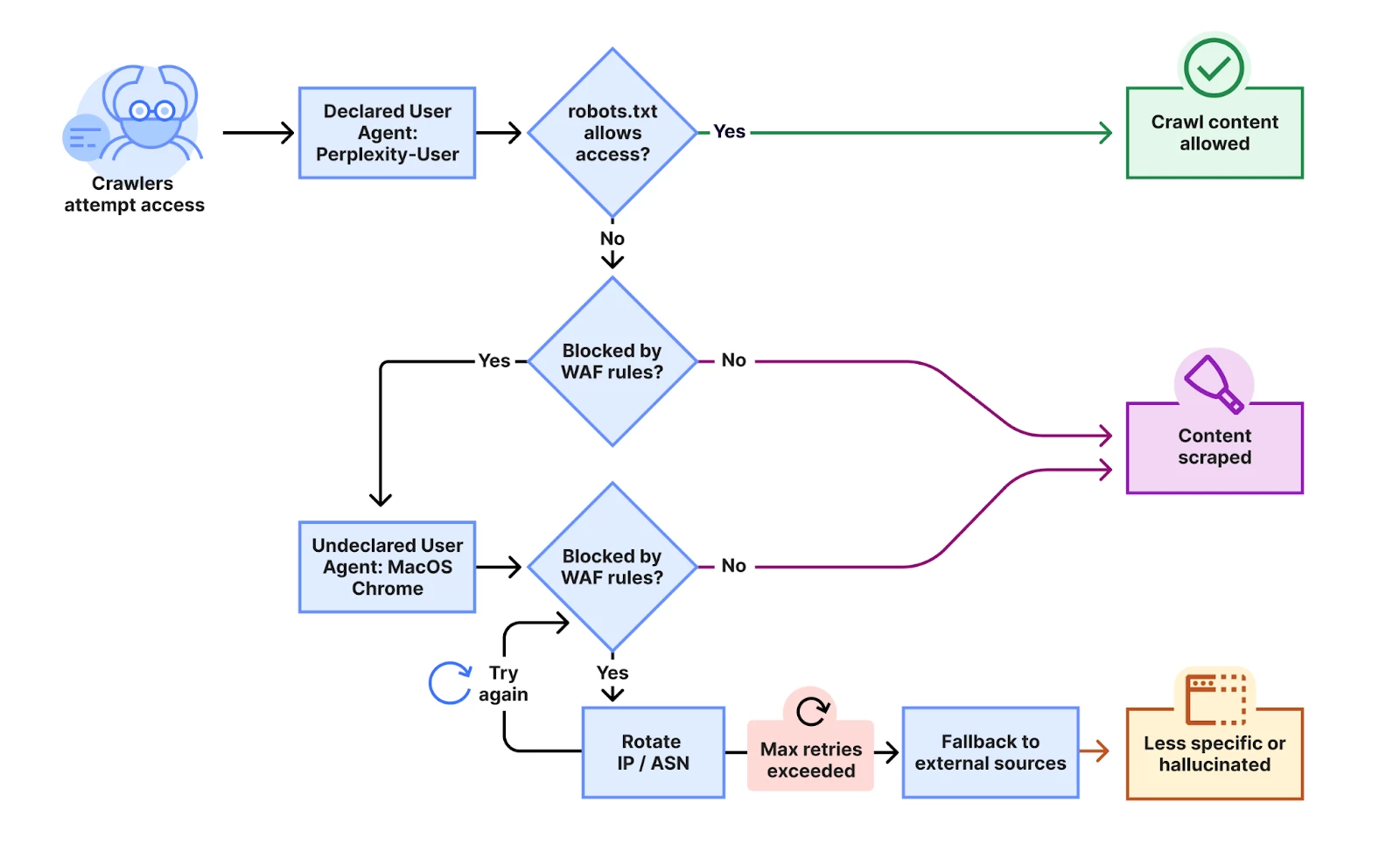
Reddit also claimed that it sent a cease-and-desist letter to Perplexity in May 2024, and that Perplexity, at the time, promised to respect Reddit"s robots.txt file. But Reddit claims the volume of citations from its platform on Perplexity has "increased forty-fold."
For the record, a similar complaint about Perplexity"s behavior was made in August by Cloudflare, alleging the AI company was ignoring robots.txt files and using stealth crawlers to get around Web Application Firewall (WAF) rules after customers tried to block its known crawlers (PerplexityBot and Perplexity-User).
{kind=link}
Back to the lawsuit, Reddit accuses Perplexity of working with "shady" scrapers and claims it set a trap to prove it: The company created a unique "test post" that was only discoverable by Google"s search crawler and inaccessible elsewhere online. Within hours, the content from that hidden post appeared in Perplexity"s search results.
Reddit wants the court to stop the defendants from scraping its data and to award damages for the harm caused, including the disgorgement of any "ill-gotten gains" earned from the unauthorized use of its content.
Perplexity is the latest AI lab to be taken to court by Reddit in its fight to control its data. Back in June, Reddit sued Anthropic for similar unauthorized data scraping, calling the Claude creator a company with two faces that publicly advocated for responsible AI while privately scraping data against its terms of service.
Update: Perplexity responded to the lawsuit on the perplexity_ai subreddit, calling out Reddit"s move as a "sad example of what happens when public data becomes a big part of a public company"s business model." The AI company claims the lawsuit is just a "show of force" intended to pressure Google and OpenAI in their own data licensing negotiations.
It also pushed back hard against the idea that it ignored licensing talks, claiming it told Reddit that, as an "application-layer company," it does not train AI models on content and never has, making a licensing agreement for that purpose impossible.
The company doubled down on its position, arguing that it simply summarizes and cites Reddit discussions, which helps users discover content, and that it "won"t be extorted" or allow itself to be used in Reddit"s "shell games" with bigger competitors.