Google has announced Gemma 4, a new family of open models built on the same underlying research as its proprietary Gemini 3. Unlike Gemini, though, the Gemma family of models is fully open source, and the Gemma 4 comes with a fully permissive Apache 2.0 license.
Perhaps one of the most significant features of Gemma 4 is the pivot towards agentic workflows. All Gemma 4 models now offer native support for function calling, structured JSON output, and native system instructions. This allows developers to build autonomous AI agents capable of reliably executing complex logic and interacting with external APIs all locally.
{kind=link}
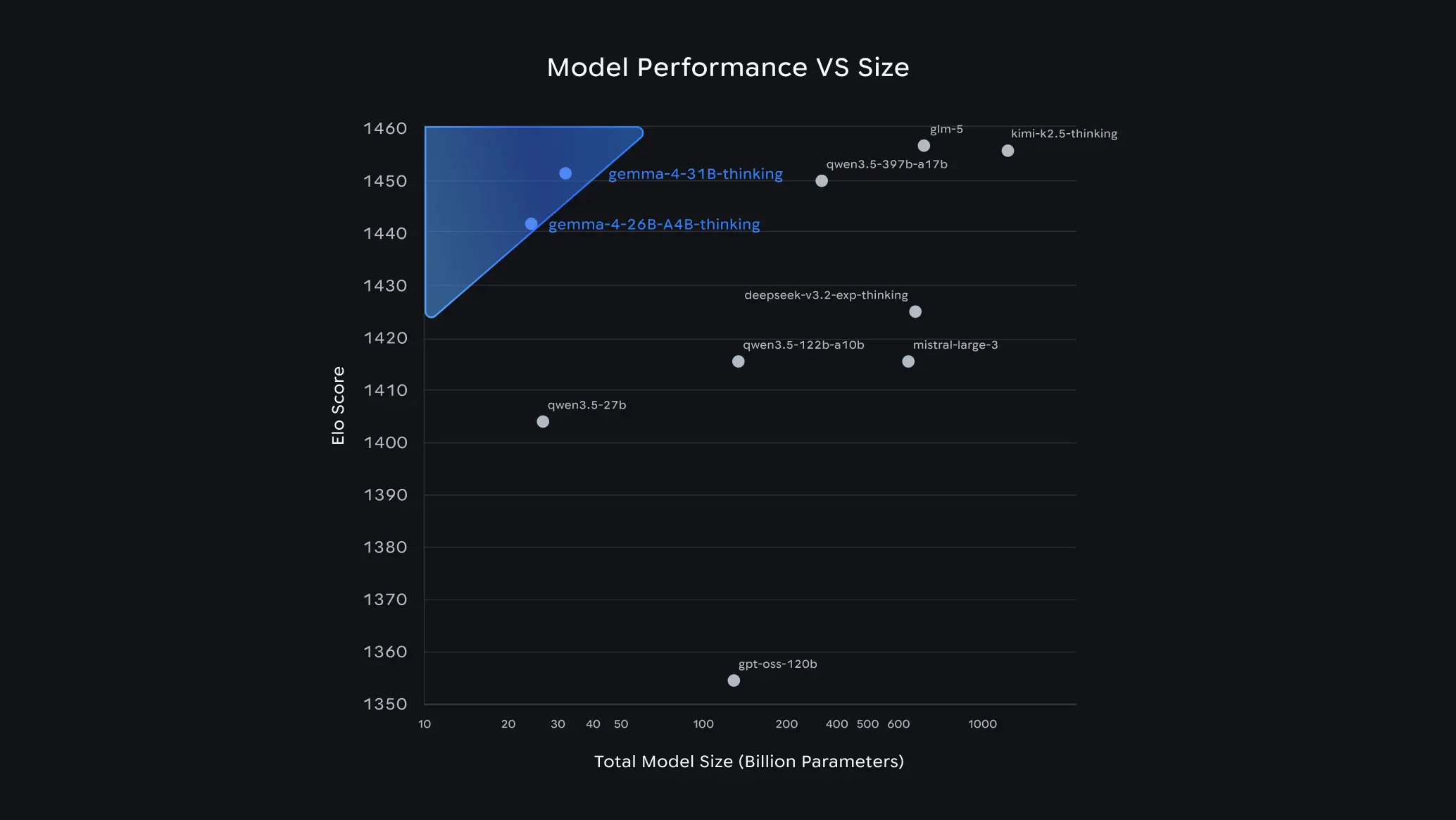
Google says that the 31B Dense model of Gemma 4 currently ranks as the #3 open model on the Arena AI leaderboard, while the 26B model holds the #6 spot, and is notably outperforming competitors up to 20 times their size. The unquantized weights for the 26B and 31B models fit neatly onto a single 80GB NVIDIA H100 GPU.
For local development, the 26B Mixture of Experts (MoE) model is hyper-optimized for latency, activating only 3.8 billion of its parameters during inference. This allows it to generate tokens lightning-fast, helpful to power local coding assistants on consumer graphics cards.
Google has also focused on multimodality of these models. Expanding on last year"s mobile-first Gemma 3n, the entire Gemma 4 family naturally processes high-resolution video and images. The E2B and E4B edge models take this a step further by featuring native audio input for seamless, near-zero latency speech recognition. These models are paired with a 128K context window for edge devices, and up to 256K for the larger 26B/31B counterparts.
Notably, unlike the previous iterations of Gemma models that came with specific terms of use and weren"t really "open-source" in the true sense, Gemma 4 comes with a commercially unrestricted Apache 2.0 license. With this, Google is directly challenging Meta’s Llama models that also come with the Apache license.
Gemma 4 is, of course, already compatible with platforms like Hugging Face, Ollama, and vLLM, alongside hardware optimization from NVIDIA, AMD, Qualcomm, and MediaTek. For mobile developers, the models are ready to prototype within the AICore Developer Preview today, ensuring forward compatibility with the upcoming Gemini Nano 4.