{kind=link}
Nvidia Research has been making strides in using deep learning to train models for various tasks. Recently, the company clocked the fastest training times for BERT and trained the largest ever transformer-based model.
However, as expected, algorithms based on deep learning require a large dataset to begin with, and that is a luxury in many situations. Along with continuing research using deep learning, the company focused its efforts in another direction as well. And the firm, at its Seattle Robotics Lab, developed a novel algorithm, called 6-DoF GraspNet, that allows robots to grasp arbitrary objects.
6-DoF GraspNet works as follows. The robotic arm observes the object and decides where to move it in 6D space (the x, y, z coordinate plane in space and three dimensions for rotation). The algorithm is designed in such a way that it generates a set of possible grips with which the object can be grasped and then moved about as needed. Then the set of possible grips is run through a "grasp evaluator" that assigns a score against each possible grip. Finally, the grasp evaluator improves the success probability of the best grip by tweaking the grasp variant with local transformations. The process is summarized in the following picture:
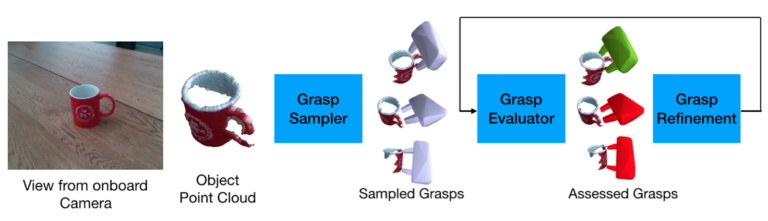{kind=link}
What is interesting here is that the researchers opted for "synthetic training data" over deep learning-based methods, that the company evaluated using the Nvidia FleX, which is a particle-based simulation technique for generating visual effects in real-time. The technique is detailed as follows in the blog post together with a GIF demonstrating the evolution of the grasps:
6-DoF GraspNet uses synthetic training data. It consists of 3D object models and simulated grasp experiences. For each object, grasp hypotheses are generated using geometric heuristics and evaluated with the NVIDIA FleX physics engine. During training, objects are rendered at random viewpoints to generate the point cloud and the simulated grasps are used to learn the parameters of the model. The model is trained on random boxes, cylinders, mugs, bowls, and bottles. The model is trained with 8 NVIDIA V100 GPUs.
According to the researchers at Nvidia, one of the biggest advantages of 6-DoF GraspNet is that it can be used to pick up arbitrary objects. Second is its modularity that allows it to be used in a variety of computer vision applications and motion-planning algorithms. Third that it can be used with a model that assigns shapes to various objects based on their "point cloud", which will ensure that the robotic arm does not collide with any obstacles in its way as they will be represented by "cubes" for the motion planning module. The results, both for isolated and crowded objects, are evident in the video embedded above.
Nvidia plans on showcasing the 6-DoF GraspNet in October/November at the International Conference on Computer Vision 2019 in Korea.
For more details, you can study the research published here.