
Last month, OpenAI announced a partnership with Cerebras, an AI startup building purpose-built systems to accelerate long outputs from AI models. At the time, OpenAI said it would integrate Cerebras’ low-latency technology into its inference stack in phases to support different workloads, including generating code and creating images.
Today, OpenAI announced a research preview of GPT-5.3-Codex-Spark, a smaller version of GPT-5.3-Codex designed for real-time coding scenarios and powered by Cerebras’ Wafer Scale Engine 3. OpenAI claims Codex-Spark can deliver more than 1,000 tokens per second while maintaining strong capability. However, since it is a smaller model, GPT-5.3-Codex-Spark is not expected to perform as well as the full GPT-5.3-Codex; OpenAI says its performance falls between GPT-5.3-Codex and GPT-5.1-Codex-Mini.
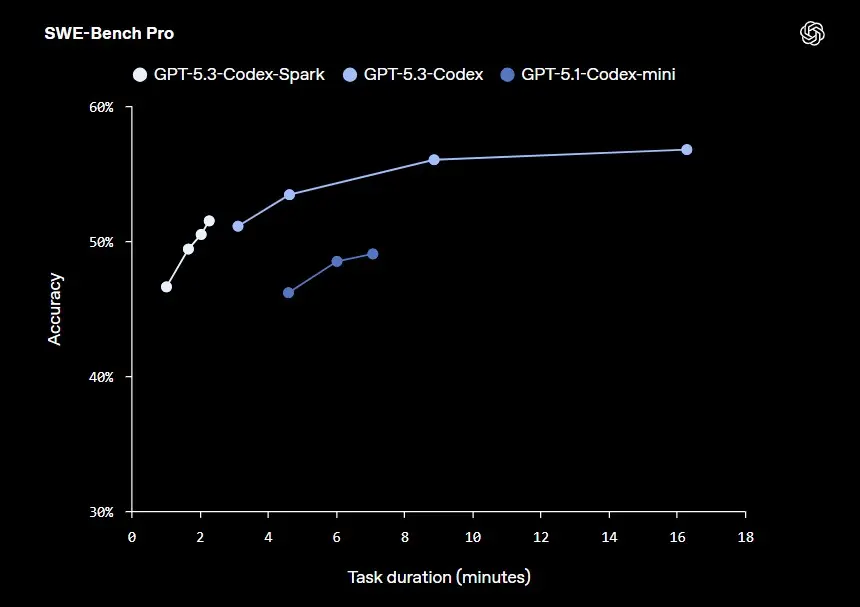
For now, Codex-Spark supports a 128K context window and text-only input. OpenAI plans to add support for larger models, longer context lengths, and multimodal input in the future. As this is a limited rollout for ChatGPT Pro users, the model will have its own rate limits, though usage won’t count toward standard limits. If demand spikes, OpenAI may further limit access or temporarily queue users to maintain reliability.
ChatGPT Pro subscribers can try the ultra-low-latency model by updating to the latest versions of the Codex app, CLI, and VS Code extension. OpenAI is also making Codex-Spark available via the API to a small set of design partners to learn how developers want to integrate it into other products and services.
OpenAI also reiterated that GPUs remain the primary compute platform across its training and inference pipelines for broad usage. However, it positioned Cerebras’ technology as a better fit for extremely low-latency Codex workloads. The company added that GPUs and Cerebras systems can also be combined within a single workload to achieve the best overall performance.




















0 Comments
Load the comments and join the conversation!
Read the comments, ask the editors questions, show respect and join the conversation.