
A team consisting of researchers from Nvidia, Arizona State University, the University of Texas, and the Barcelona Supercomputing Centre have published a paper studying ways of bypassing the recent deceleration in the pace of advancement of transistor density.
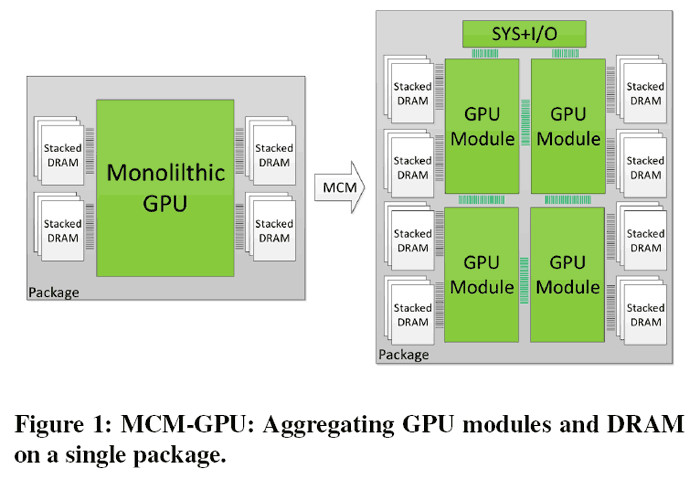
To avoid the performance ceiling monolithic GPUs will ultimately reach, they propose the manufacture of basic GPU Modules (GPMs) that will be integrated on a single package using high bandwidth and power-efficient signaling technologies, in order to create Multi-Chip-Module (MCM) GPU designs.
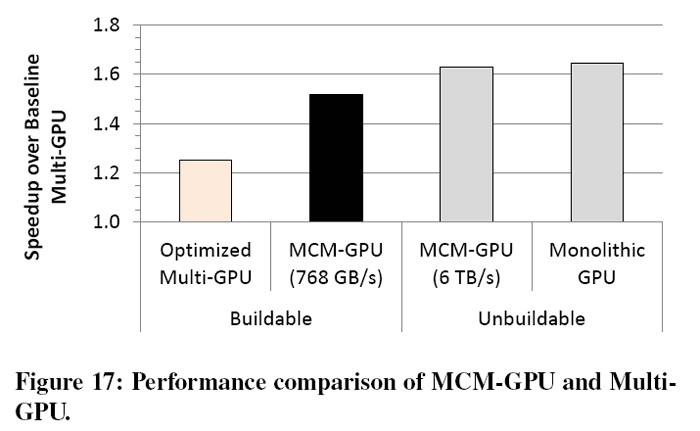
The researchers used Nvidia's in-house GPU simulator to evaluate their designs. According to their findings, MCM GPUs can greatly assist in increasing the number of Streaming Multiprocessors (SM), a fact that speeds up vastly many types of applications. Utilizing the simpler GPM building blocks and advanced interconnects, they simulated a 256 SM chip that achieves a 45.5% speedup over the largest possible monolithic GPU with 128 SMs. In addition, their design performs 26.8% better than a discrete multi-GPU with the same number of SMs, and is within 10% of the performance of a hypothetical monolithic GPU with 256 SMs that cannot be built based on today’s technology roadmap.
Source and Images via Hexus





















7 Comments
Load the comments and join the conversation!
Read the comments, ask the editors questions, show respect and join the conversation.